Creating your own Vector Search engine
In this article, we'll dive deeper into creating your own vector search engine. Mainly, we'll look at the tokenization and vectorization process.


Search has become an indispensable part of on-site experiences. Searching for products, content, and settings is now ubiquitous, but providing relevant results remains a challenge for many businesses. Traditional full-text search engines struggle with unstructured content, such as text documents or databases. The sheer volume and complexity of available data can overwhelm these algorithms, especially for large businesses with hundreds of thousands of products or pieces of content. Vector search engines aim to resolve this issue of relevancy.
What are Vector search engines?
Vector databases are specialized databases designed to store and organize numerical vectors or vector data. These databases use a set of mathematical functions for searching, indexing, and retrieving specific information based on input search queries.
Unstructured data refers to any data that does not conform to a predefined format or structure, such as text and images. In vector databases, unstructured data like text and images can be managed using techniques similar to those used in traditional relational databases, such as SQL. However, vector databases use numerical vectors instead of tables and rows.
One key benefit of vector databases is their ability to efficiently manage large volumes of unstructured data. They rely on mathematical operations rather than tables, significantly improving query performance and reducing storage requirements. Another important role of vector databases is to provide powerful search capabilities. Vector databases can accurately match search queries against relevant vectors and generate meaningful results.
The Difference Between Text Search and Vector Search
Full-Text Search engines locate exact, partial, or similar matches within large document collections. They rely on indexing mechanisms to quickly process match queries. However, they can fall short when dealing with the semantic meaning behind search terms. A full-text search engine will effectively match phrases and keywords but will fail to provide relevant results to natural language questions.
In contrast, vector search engines are optimized for pattern recognition and extracting meaning from unstructured textual data. While they may not always be as fast as full-text search engines, they often excel in scenarios involving natural language queries.
For example, consider a user searching for running shoes online. Instead of simply typing in "male running shoe," the user might type "what is the best shoe for running." The natural language nature and different word order can easily result in a full-text search engine delivering irrelevant results. A well-trained vector-based search engine could return relevant results by considering the query's semantic meaning. With enough trained data, the different phrases in the query can be identified as "features" relevant to the product.
How does a Vector Search Database work in practice?
Full-text search directly matches an input query to the text of stored documents. In contrast, a vector search engine converts any input into numerical vectors and matches these vectors against the vector values of the stored documents. The more closely a given vector matches between a document and the query, the more relevant they are to each other. This process leverages mathematical formulas, enabling fast queries. However, it's essential to note that the vectorization process must be completed before the documents can be queried.
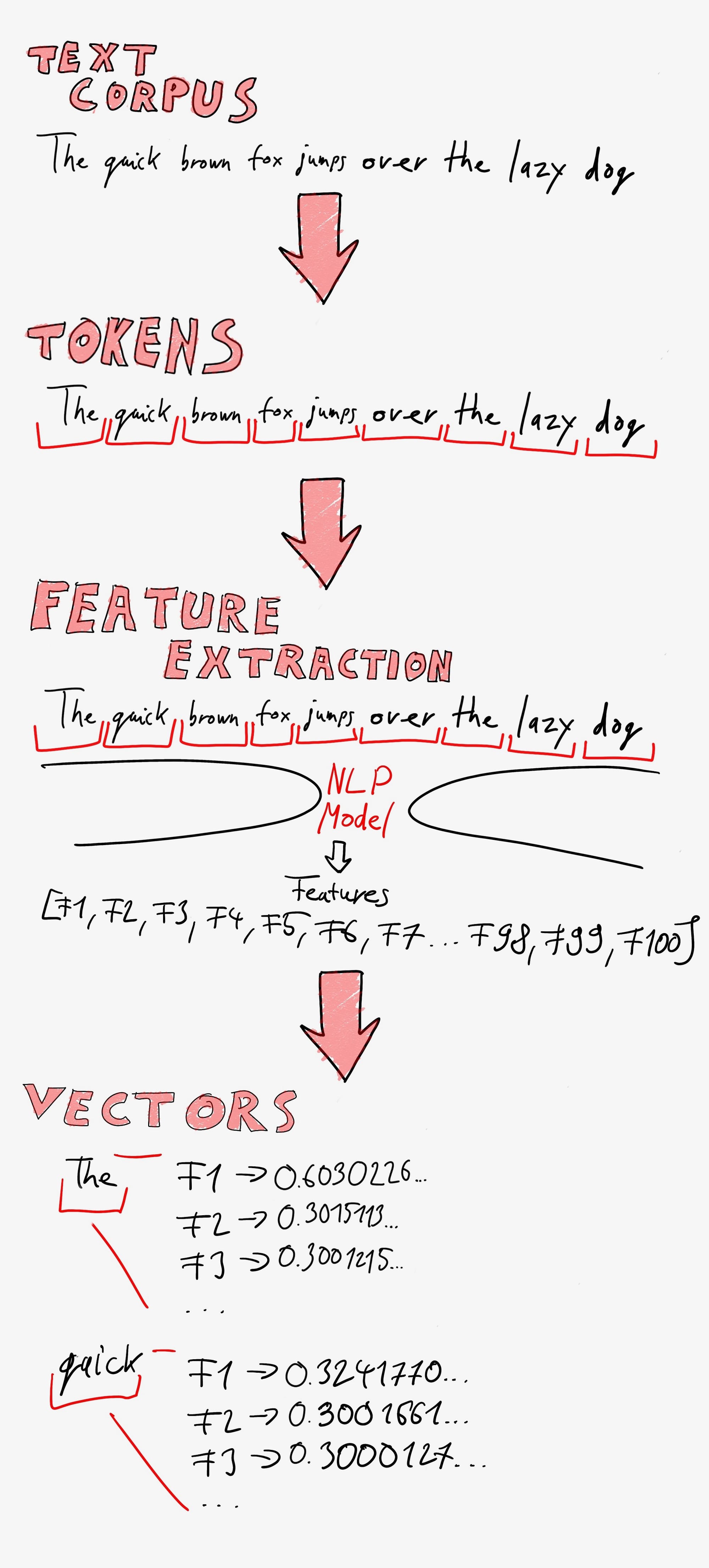
This leads us to the critical process of feature extraction, where the transformation from text to vectors takes place.
First, the input documents (text corpus or text corpora for plural) need to be tokenized, which means breaking them up into words and phrases. These tokens are then vectorized, meaning each token is assigned a series of numerical values, known as vectors, based on features extracted by an NLP model. For example, when the sentence "The quick brown fox jumps over the lazy dog" is tokenized, the tokens will be 'The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog'.
During feature extraction, each token is transformed into a fixed-size vector. This process captures the semantic meaning of the text and boils it down to a manageable and consistent format.
Feature extraction is the process of converting text into numerical representations (vectors) that a model can process. Several models can be used for this transformation, each with its own strengths and applications:
- Bag of Words (BoW)
This model creates vectors by representing the presence or absence of words in a corpus. Although simple, it doesn't capture the meaning or order of words. - TF-IDF (Term Frequency-Inverse Document Frequency)
This model improves on BoW by taking into account the frequency of words and their importance relative to the entire corpus. It's widely used for information retrieval and text mining. - Word2Vec
Developed by Google, Word2Vec captures semantic meaning by training on large text corpora to understand word context. It creates dense vectors where similar words are close in the vector space. - GloVe (Global Vectors for Word Representation)
Similar to Word2Vec, GloVe captures global corpus statistics and quantifies the meaning of words into vectors. - BERT (Bidirectional Encoder Representations from Transformers)
One of the most advanced models, BERT understands context in both directions (before and after a word). It provides deep and nuanced embeddings for words and entire sentences.
During vectorization, each token receives a series of vector values for each 'feature'. These values are determined by how relevant each token is to nearby tokens, the frequency of the tokens, and other factors.
Below is a diagram that illustrates this feature the full vectorization process:
Now, let's dive deeper into running queries using a vector search engine.
How do vector search engines run queries?
Before looking at the query process, it's crucial to understand what vectors are in this context. Vectors can be thought of as points in a multi-dimensional space, where each dimension represents a feature or characteristic derived from the text. For example, in a 3D space, a vector might be represented as a point with coordinates (x, y, z). However, in the context of text data, the space often has hundreds or thousands of dimensions, each corresponding to a unique term in the corpus.
This is a simplified visualization of a vector, as a point with 3 values [x,y,z] on a 3D coordinate system.
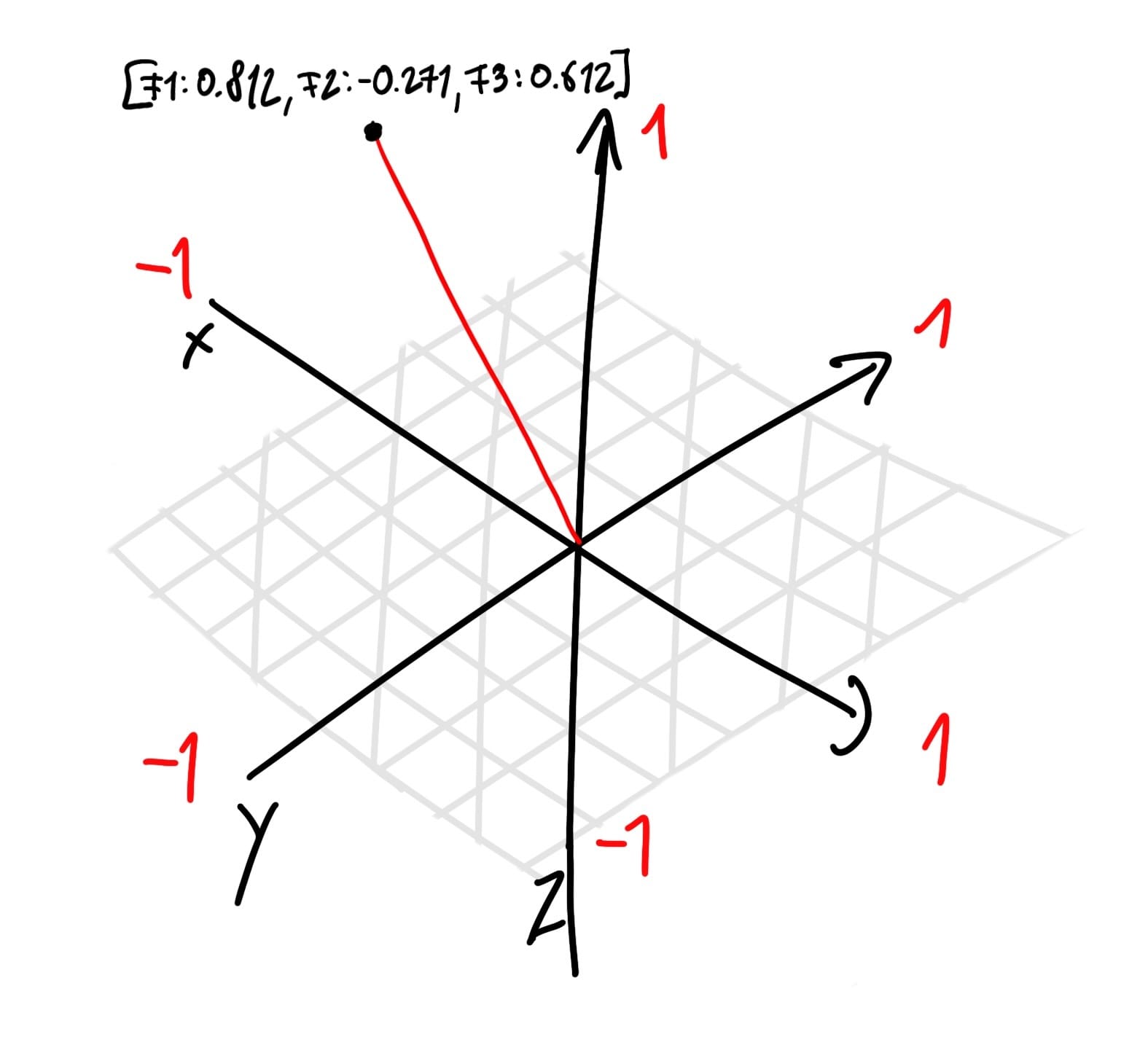
Since features extraction can result in 100s of features, each vector will have more than 3 dimensions.
How are vectors compared?
In vector search engines, comparing vectors is essential to measure the similarity between a query and documents. One of the most commonly used methods for comparing vectors is cosine similarity.
Cosine similarity measures the cosine of the angle between two vectors, providing a measure of how similar they are.
The value ranges from -1 to 1:
- 1: Vectors are identical in direction.
- 0: Vectors are orthogonal (no correlation).
- -1: Vectors are diametrically opposed (completely dissimilar).
Since vectors represent the tokens' relevancy to the extracted features, the higher the cosine similarity between two vectors, the more relevant they are to each other. By comparing all features between a vectorized input query and the text corpus, we can determine the most relevant results efficiently through mathematical computation.
Creating our own vectorization framework
The text corpus should contain a variety of sentences or documents that represent the type of content you expect to process. It serves as the training data for the Word2Vec model. The more diverse and comprehensive the corpus, the better the model can capture semantic relationships between words.
Example Text Corpus:
text_corpus = [
"The quick brown fox jumps over the lazy dog",
"I love machine learning and natural language processing",
"Word2Vec is a powerful technique for vectorizing text"
]
What is tokenization and why do we need it?
Tokenization is the process of splitting text into individual words or tokens. This is a crucial step because machine learning models process text data in tokenized form. By breaking down sentences into tokens, we can analyze and process each word individually.
tokenized_corpus = [word_tokenize(sentence.lower()) for sentence in text_corpus]
How is the model trained?
The Word2Vec model is trained on the tokenized corpus. During training, the model learns to map words to vectors in such a way that words with similar meanings are close to each other in the vector space.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(tokenizer=word_tokenize)
X = vectorizer.fit_transform(text_corpus)
Parameters:
**sentences**: The tokenized corpus used for training.**vector_size**: The size (dimensionality) of the word vectors. Defines the number of dimensions in which words will be represented. Larger sizes capture more information but require more data and computation.**window**: The maximum distance between the current and predicted word within a sentence. It determines how many words to the left and right of the target word are considered. Larger windows capture broader context but might introduce noise.**min_count**: Ignores all words with total frequency lower than this. Filters out infrequent words to reduce noise and improve performance. Words that appear fewer times than themin_countvalue are ignored.**sg**: Defines the training algorithm.1for skip-gram;0for CBOW (Continuous Bag of Words). Skip-gram (sg=1) predicts surrounding words given the current word. CBOW (sg=0) predicts the current word given surrounding words.
Step 1: Vectorize the Search Query
Tokenize the query and convert each token to its corresponding vector using the trained Word2Vec model. Then, average the vectors of the tokens to obtain a single vector representing the query.
def vectorize_query(query, vectorizer):
tokenized_query = word_tokenize(query.lower())
query_vector = vectorizer.transform([query])
return query_vector
Step 2: Calculate Document Vectors
Convert each document in the corpus into vectors using the same method as the query.
doc_vectors = [
vectorizer.transform([doc])
for doc in text_corpus
]
Step 3: Calculate Cosine Similarity
Compare the query vector with each document vector using cosine similarity. Cosine similarity shows how similar two vectors are by measuring the angle between them in multi-dimensional space. The closer the angle is to zero, the more similar the vectors are. This method allows us to determine which documents are most relevant to the query based on their vector representations.
from sklearn.metrics.pairwise import cosine_similarity
def find_most_similar(query_vector, doc_vectors):
similarities = cosine_similarity(query_vector, doc_vectors)
most_similar_index = np.argmax(similarities)
return most_similar_index
Step 4: Find and Output the Most Similar Document
Identify the document with the highest similarity score as the most relevant to the query.
most_similar_index = find_most_similar(query_vector, doc_vectors)
print(f"Search Query: {search_query}")
print(f"Most Similar Document: {text_corpus[most_similar_index]}")
The full script:
import sys
import numpy as np
import nltk
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from nltk.tokenize import word_tokenize
# Download NLTK resources
nltk.download('punkt')
# Sample text corpus representing the type of content you expect to process
text_corpus = [
"The quick brown fox jumps over the lazy dog",
"I love machine learning and natural language processing",
"Word2Vec is a powerful technique for vectorizing text"
]
# Step 1: Tokenize the corpus and vectorize it using TF-IDF
print("Vectorizing the corpus using TF-IDF...")
vectorizer = TfidfVectorizer(tokenizer=word_tokenize)
X = vectorizer.fit_transform(text_corpus)
# Get the feature names (terms)
features = vectorizer.get_feature_names_out()
print(f"Features: {features}")
# Print the TF-IDF matrix with feature names
print("TF-IDF Matrix:")
tfidf_matrix = X.toarray()
for doc_idx, doc_vector in enumerate(tfidf_matrix):
print(f"Document {doc_idx}:")
for feature_idx, feature_value in enumerate(doc_vector):
if feature_value > 0:
print(f" {features[feature_idx]}: {feature_value}")
# Step 2: Vectorize the Search Query
def vectorize_query(query, vectorizer):
print(f"Vectorizing the query: {query}")
query_vector = vectorizer.transform([query])
print(f"Query Vector: {query_vector.toarray()}")
return query_vector
# Step 3: Calculate Cosine Similarity
def find_most_similar(query_vector, X):
print("Calculating cosine similarity...")
similarities = cosine_similarity(query_vector, X)
print(f"Similarities: {similarities}")
most_similar_index = np.argmax(similarities)
print(f"Most similar document index: {most_similar_index}")
return most_similar_index
# Step 4: Find and Output the Most Similar Document
def main():
if len(sys.argv) < 2:
print("Please provide a search query as a parameter.")
sys.exit(1)
search_query = " ".join(sys.argv[1:])
print(f"Search Query: {search_query}")
query_vector = vectorize_query(search_query, vectorizer)
most_similar_index = find_most_similar(query_vector, X)
print(f"Most Similar Document: {text_corpus[most_similar_index]}")
if __name__ == "__main__":
main()
Try it out:
Trying the above code out will simulate a very basic vector search engine, by searching for the passed string within the previously vectorized documents. Copy the above file & save it as vector_search.py to an empty folder & navigate to it using the terminal. Set up & activate a new virtual env using venv:
python3 -m venv venv &&
source venv/bin/activate
Install dependencies:
pip install --upgrade pip &&
pip install nltk numpy scikit-learn
Run the script & pass a search string as an argument.
python vector_search.py "machine learning"
This will out out something like this:
[nltk_data] Downloading package punkt to /Users/bzatrok/nltk_data...
[nltk_data] Package punkt is already up-to-date!
Vectorizing the corpus using TF-IDF...
/Users/myuser/dev/test/venv/lib/python3.12/site-packages/sklearn/feature_extraction/text.py:521: UserWarning: The parameter 'token_pattern' will not be used since 'tokenizer' is not None'
warnings.warn(
Features: ['a' 'and' 'brown' 'dog' 'for' 'fox' 'i' 'is' 'jumps' 'language' 'lazy'
'learning' 'love' 'machine' 'natural' 'over' 'powerful' 'processing'
'quick' 'technique' 'text' 'the' 'vectorizing' 'word2vec']
TF-IDF Matrix:
Document 0:
brown: 0.30151134457776363
dog: 0.30151134457776363
fox: 0.30151134457776363
jumps: 0.30151134457776363
lazy: 0.30151134457776363
over: 0.30151134457776363
quick: 0.30151134457776363
the: 0.6030226891555273
Document 1:
and: 0.3535533905932738
i: 0.3535533905932738
language: 0.3535533905932738
learning: 0.3535533905932738
love: 0.3535533905932738
machine: 0.3535533905932738
natural: 0.3535533905932738
processing: 0.3535533905932738
Document 2:
a: 0.3535533905932738
for: 0.3535533905932738
is: 0.3535533905932738
powerful: 0.3535533905932738
technique: 0.3535533905932738
text: 0.3535533905932738
vectorizing: 0.3535533905932738
word2vec: 0.3535533905932738
Search Query: fast fox and dog
Vectorizing the query: fast fox and dog
Query Vector: [[0. 0.57735027 0. 0.57735027 0. 0.57735027
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. ]]
Calculating cosine similarity...
Similarities: [[0.34815531 0.20412415 0. ]]
Most similar document index: 0
Most Similar Document: The quick brown fox jumps over the lazy dog
What does this all mean?
The output of this code provides detailed information about the tokenization and vectorization process. This verbosity helps in understanding how the text data is being processed and transformed into a format suitable for machine learning algorithms.
Features
This line tells us which 'features' or unique tokens the vectorizer has identified as dimensions for our vectors:
Features: ['a' 'and' 'brown' 'dog' 'for' 'fox' 'i' 'is' 'jumps' 'language' 'lazy'
'learning' 'love' 'machine' 'natural' 'over' 'powerful' 'processing'
'quick' 'technique' 'text' 'the' 'vectorizing' 'word2vec']
TF-IDF Matrix
The lines below list the various features and their significances found in each document:
TF-IDF Matrix:
Document 0:
brown: 0.30151134457776363
dog: 0.30151134457776363
fox: 0.30151134457776363
jumps: 0.30151134457776363
lazy: 0.30151134457776363
over: 0.30151134457776363
quick: 0.30151134457776363
the: 0.6030226891555273
Document 1:
and: 0.3535533905932738
i: 0.3535533905932738
language: 0.3535533905932738
learning: 0.3535533905932738
love: 0.3535533905932738
machine: 0.3535533905932738
natural: 0.3535533905932738
processing: 0.3535533905932738
Document 2:
a: 0.3535533905932738
for: 0.3535533905932738
is: 0.3535533905932738
powerful: 0.3535533905932738
technique: 0.3535533905932738
text: 0.3535533905932738
vectorizing: 0.3535533905932738
word2vec: 0.3535533905932738
Query Vectorization and Similarity Calculation
Finally, the query we passed, 'fast fox and dog', was vectorized and then queried against the documents:
Search Query: fast fox and dog
Vectorizing the query: fast fox and dog
Query Vector: [[0. 0.57735027 0. 0.57735027 0. 0.57735027
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. ]]
Calculating cosine similarity...
Similarities: [[0.34815531 0.20412415 0. ]]
Most similar document index: 0
Most Similar Document: The quick brown fox jumps over the lazy dog
The only matching words were 'dog' and 'fox', which produced high values, as opposed to the 0s for tokens not present in the three documents. This indicates that the first document is the most similar to the query based on the cosine similarity measure.
Where Do We Go From Here?
While there are tangible gains from using vector queries as they are, to greatly improve relevancy, we need to fine tune the process. We'll do this in a later article. Stay tuned!
If you like what I do, buy me a beer: